こんにちは、びしょ〜じょです。 年明けに買った対洗濯物用乾燥機のおかげで窓を開けたりカーテンレールにハンガーを吊るす日々が終わりました。 ところで2月分の電気代はすでに1月分を越えようとしています。
1. はじめに
今年は4年次なので卒業研究! ということでjoin pointを追加したコンパイラ中間言語の設計と、その上での最適化を定義してやっていきました。 実装はこちら
卒研発表をスライドを作るためにも、何をしたかを噛み砕いて文に起こしてみたいと思います。
2. 関連研究
PLDI 2017で『Compiling without Continuations』1という発表がありました。 継続の緑の本をもじったタイトルですが、CPSと直接戦っている感じではないです。 join pointと呼ばれるものを明示的に扱うことでコードサイズの爆発を抑えたり高速に動作するターゲット言語に変換しようという試みです。
2-1. join pointとは
プログラム2.1における分岐した制御フローが合流する場所をjoin pointと呼ぶ。 あるいは制御フローグラフ2.2の赤点で囲んだ部分。
let j4 x = e4 in let j5 y = e5 in
if e1 then (if e2 then j4 m else j5 n
else (if e3 then j4 o else j5 p)
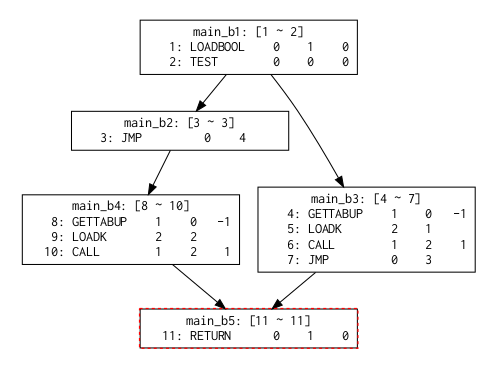 図2.2 制御フローグラフ
図2.2 制御フローグラフ
CPSでは継続になるし、ANFではコード複製で表現することになる。 ここで最適化するとコードサイズがボワーっとなってしまう。 そこでMaurerらは\(\text{System F}_J\)という、合流点を明示的に扱う中間言語を提案した。 合流点を用いることでコードサイズの爆発が抑えられ、さらに再帰的な合流点を用いることでstream fusionができることを示した。
しかしSystem Fjは純粋な必要呼びの、Haskellのような言語を対象としたコンパイラ中間言語として設計されたので、ジャバなどの広く使われているプログラム言語とはギャップがある。
3. 本研究
System Fjとその困った点を踏まえて、非純粋な値呼びの、明示的な合流点を持つコンパイラ中間言語\(Joel\)を提案する。 非純粋性として、多くのプログラム言語で使われており、合流点と競合しそうなコントロールエフェクトを持っている例外を追加した。
例外を考慮した最適化を定義した。 評価コンテキストをばらまく、commuting conversionの一種である最適化がtry-with式の位置を変えてトライキャッチプリキュアのメタモルフォーゼに失敗してプログラムの意味が変わってしまうのを防ぐために、 try-with式の含まれない評価コンテキストを新たに定義し、最適化規則に用いた。
4. 性能評価
Joel上の最適化を評価するため、CPS上で最適化されて生成されたターゲット言語との比較をおこなった。 ソース言語にはOCamlのサブセットであるCore MLを新たに定義し、!!!!ターゲット言語はOCamlとした。!!!! これがあまりよくなかった。
CPSも、Double-Barreled CPSをもとに複数の例外をハンドルできるような体系を新たに定義した。
4-1. 追記20180321
ここからしばらく嘘が書いてある!! ので途中は飛ばしてください。 おわり
stream fusionがうまくいったけど全然速くならなかったという結果でした(このへんの例)。 予備実験をすべきでしたが、つまるところ以下の例がOCamlではほとんど同じ速度で実行されます。
let map f xs =
let rec work = function
| x :: xs -> f x :: work xs
| [] -> []
in work xs
let fold f z xs =
let rec work z = function
| x :: xs -> work (f z x) xs
| [] -> z
in work z xs
let test1 arg =
fold (+) 0 (map (fun x -> x * x) arg)
let test2 arg = fold (fun x y -> x + y * y) 0 arg
なんでOCamlこれ同じ速度で動くんだ、分からんということでここからなんとかしなければならない…。
ちなみにmapを20回くらいやったものと(fun x y -> x + (y * y * y * y * ... * y))をfoldに渡すものだと実行速度に差が出ました。
同じようなコードをLuaで書いたら即差が出ましたので、ターゲット言語によってはしっかり実行速度に関してアドが言えるんじゃないでしょうか。
追記20180321
私の手抜きが原因でした。
この記事で書いたようなものを使ってベンチマークを取っていた(!!!!)わけですが、
どうやらexecute_phraseは何回も実行していくうちに遅くなる(???)ということが後に発覚したため、ベンチマーク周りを0から再実装しました…。
よくわからないと思いますがボクもよくわからないので、とりあえず皆さんお手元で試してみてください。
仕切り直しです。 Haskellならともかく、OCamlはstream fusionなんてやらないぜ。 core_benchで試してみましょう。
open Core_bench.Std
let map f xs =
let rec work = function
| x :: xs' -> f x :: work xs'
| [] -> []
in work xs
;;
let foldl f z xs =
let rec work z = function
| x :: xs' -> work (f z x) xs'
| [] -> z
in work z xs
;;
let fused mapf foldf z xs =
let rec work z = function
| x :: xs' -> work (foldf z @@ mapf x) xs'
| [] -> z
in work z xs
;;
let () =
Random.self_init ();
let open Core_bench.Test in
let double x = x * x in
let arg = Array.(init 10000 (fun _ -> Random.int 10000) |> to_list) in
Core.Command.run @@ Bench.make_command [
create ~name: "map" (fun () -> ignore @@ map double arg);
create ~name: "foldl" (fun () -> ignore @@ foldl (+) 0 arg);
create ~name: "mapfold" (fun () -> ignore @@ foldl (+) 0 @@ map double arg);
create ~name: "fused" (fun () -> ignore @@ fused double (+) 0 arg)
]
うん
$ ocamlfind ocamlopt -package core_bench -linkpkg -thread test.ml
$ ./a.out -ascii
Estimated testing time 40s (4 benchmarks x 10s). Change using -quota SECS.
Name Time/Run mWd/Run mjWd/Run Prom/Run Percentage
--------- ---------- ------------ ---------- ---------- ------------
map 139.93us 30_004.72w 2.03kw 2.03kw 87.99%
foldl 37.26us 5.00w 23.43%
mapfold 159.04us 30_009.71w 1.79kw 1.79kw 100.00%
fused 49.41us 6.00w 31.07%
注目すべきは下2つですね。
mapfoldは読んで字の如くmapしてfoldしてます。
fusedはmapに渡す関数とfoldに渡す関数を一気に適用してるので中間リストを生成しないしtail recursionだし良いね。
実行速度の差が無いって言ったやつ誰やねん…。
1つのベンチマークのうちに実行速度にだいぶ差があるベンチマーク関数があるとTime/Runの表示がだいぶ怪しい数字を出すことも分かったので、結局卒論提出版ではcore_benchのソースを参考にしてお手製ベンチマークで切り抜けました。おわり。
生成されるコードサイズに関しては、Joelによる最適化を経て得られたものが一番小さかったので、そこはadvantageがあったと言えます。
5. おわりに
終わらないんだよなぁ…
-
Luke Maurer, et al. Compiling without Continuations. https://dl.acm.org/citation.cfm?id=3062380 ↩
投稿されたコメントはCC BY 4.0ライセンスの下で公開されます。