あけましておめでとうございます、びしょ~じょです。 これは言語実装Advent Calendar2022 17日目の記事です。 諸事情ありましたが端的に申し上げると私の怠慢で大幅に投稿日が遅れました。
1. はじめに
OCaml 5.0が去年末にリリースされた。 並列処理のプリミティブに加え、algebraic effectsを用いた並行処理も書けるようになり、これはとても素晴らしいことですよ。 本日はOCaml 5.0のベースとなるMulticore OCamlにおけるalgebraic effectsの実装論文『Retrofitting Effect Handlers onto OCaml』[1]について解説する。 該当論文ではeffect handlersの実装デザインにあたって以下の4つを考慮している:
-
Backward compatibility
存のコード資産に(表層構文はもちろん一切、ランタイムパフォーマンスはほとんど)影響をあたえない
-
Tool compatibility
バッガやプロファイラなどがこれまで同様に使えるように。DWARF unwind tableを利用したstac inspectionなど
-
Effect handler efficiency
言語組み込みの並行機構となるので、スピードを重視する
-
Forwards compatibility
modularityの理念に基づいて、ブロッキングI/Oのあるコードもeffect handlersを利用して透過的に非同期化できること
互換性の重視も本論文および実装の大きなcontributionとなっているが、今回は特にalgebraic effect handlersの実装部分に焦点を当てる。
2. OCamlの例外は速い
様々なプログラム言語でtry-catchなどによる例外処理は遅いというのはよく聞くだろう。
その一方、OCamlの例外は速いという話は聞いたことがあるかもしれない。
まあランタイムが異なるので例外処理の速度だけ比較しようもないのでなんとも言えないが、OCamlは例外処理コストをおさえる工夫をしている。
2-1. OCamlはC calling conventionに従わない
OCamlはC calling conventionに従わないのでtry-catchが速くなる。
どういうことだろう。
具体的には、OCamlはcallee-saved registersを利用しない。
callee-saved registersを使わないことにより、try節の中を評価する前にレジスタを保存する必要がない2。
同様に、try節から抜けるときにもレジスタを戻す操作も不要である。
つまり、例外ハンドラの導入はハンドラのprogram counter(pc)と現在のコンテキストの例外ハンドラへのポインタ(exn_ptr)をスタックにpushするだけでよいのだ(図2.1)。
そして、現在のexn_ptrはstack pointer(rsp)に更新され、図2.1(c)の矢印が指すように例外ハンドラのフレームが連結リストとして作られていく。
例外を発生させるときは、rspをexn_ptrにセットしてexn_ptrを読んでpcに飛ぶことで最寄りのハンドラにキャッチされる。
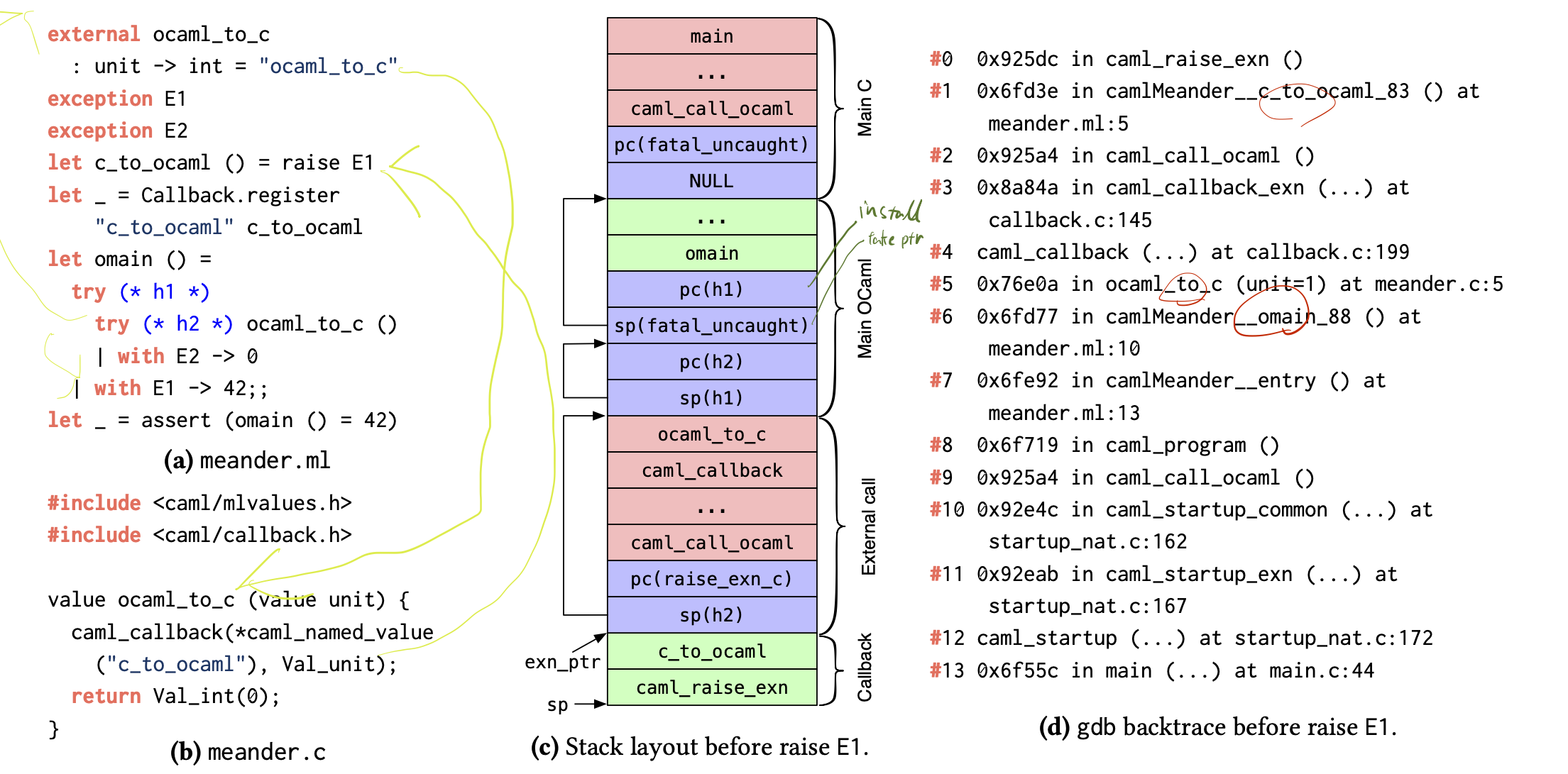 図2.1 Program stack on stock OCaml ([]より引用、筆者メモつき)[^3]
図2.1 Program stack on stock OCaml ([]より引用、筆者メモつき)[^3]
ちなむと、x86_64バックエンドではcallee-saved registersであるr15とr14をそれぞれallocation pointerとCaml_stateへの参照として利用している。
Allocation pointerとは、bump pointer3のallocationに使われるマイナーヒープへのポインタ、Caml_stateはランタイムのグローバル変数を管理するテーブルである。
なるほど確かに、例外ハンドラの導入および例外発生は軽量そうである。 数字で見てみるとこういう感じ4。
3. Effect invocation & handlingも速そう
筆者も「Algebraic effect handlersは復帰可能な例外」という話を多々してきた。 なので速い例外がインプリできるならeffect handlersも速い実装ができそうだという直感がある。 果たして直感はそのとおりで、callee-saved registersを利用しないため、handled-expressionの評価に入るときもeffectを発生させるときに保存すべきregistersは無く、effectをハンドルするときもcontinuationを走らせるときもrestoreすべきregistersが無い。 既存のOCamlのランタイムデザインが、幸運にもalgebraic effect handlersの導入にも生きたのであるなぁ〜。
4. Red Zone in fibers
Multicore OCamlでは(並行計算における)スレッドの実行単位をfiberと呼んでいる。 fiberは図4.1(a)のようになる。
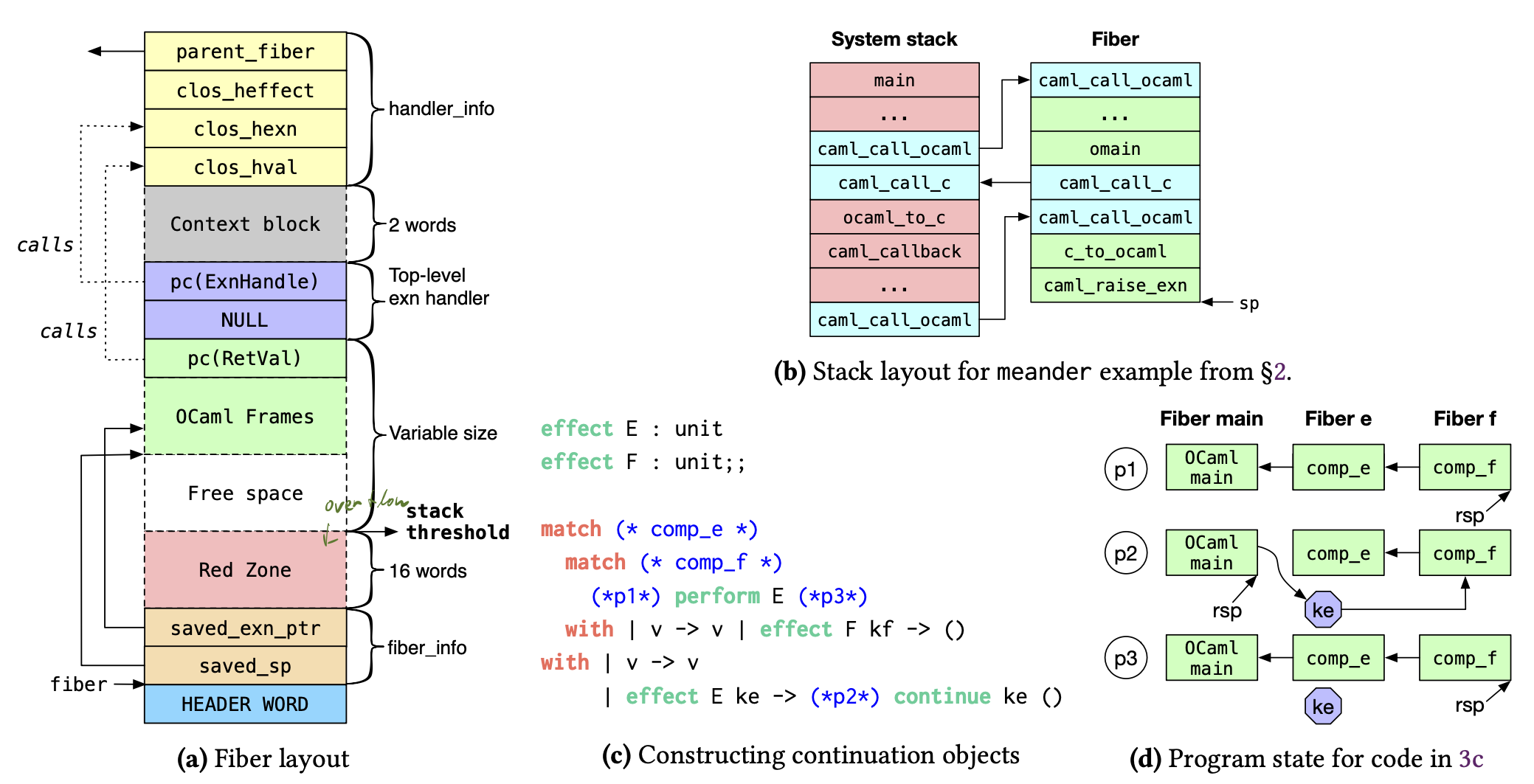 図4.1 Layout of Multicore OCaml effect handlers ([]より引用、筆者メモつき)
図4.1 Layout of Multicore OCaml effect handlers ([]より引用、筆者メモつき)
OCaml frames部分が可変長となっているので、fiberのサイズも同様に可変となる。
Fiberのサイズは小さくしたいので、このスペースの初期値はまず16 wordsにしておく。
Stack pointer rspが図中のstack thresholdを下回るときoverflow状態とみなし(stackは下方に伸長する)、2倍のサイズを確保した領域にfiberをコピーする。
Multicore OCamlではstack overflow checkをOCaml関数のfunction prologueに導入した。
ただ、overflowはあまりおきないため、CPU branch predictionでほとんど解消される。
とはいえ毎度の関数呼び出しでチェックするのはランタイムコストがかさむ。 ところで、多くの実用的なOCamlプログラム5では多くの関数はそれ以上別の関数を呼ばないleaf functionsであることが観察されており、これはframe sizeが充分小さい。 つまりほとんどstack overflow のチェックをする必要はないんじゃないか? そこで、固定長のred zoneをstack topに追加する。 Red zoneよりサイズを下回るframeを持つleaf functionsに対してcompilerはstack overflow checkを挟まないようにした。 このred zoneのサイズは16 wordsであり、理由については後述する。
5. ベンチマーク
5-1. With no effects
Effectを利用していない既存のプログラムはどれくらい影響を受けるのか。 元のOCamlのベンチマークをbaselineとして、Multicore OCaml、red zoneを0 wordsにしたもの(毎度stack overflow checkが入る)、red zoneを32 wordsにしたものと3種類に対してmacro benchmarkをおこなった。 中にはCoqやmenhir、irminなど実用されている大規模なプログラムも多く含む。 アロケータとGCの挙動の違いにより実行速度が増減するケースがいくつかあったが、実行時間の結果は平均して1%弱の実行時間増加に収まった。 54個のプログラムのうち32個は5%未満のオーバーヘッドに収まり、8つは10%以上になった。
fibやtakなどを利用したmicro benchmarkでは実行時間と実行される命令数を比較した。 例外の発生や補足は実行時間や命令数に大きな変化はなかったが、Cの関数呼び出しやCからのcallbackは実行時間も命令数も大きく増えた。 前者に関しては、Multicore OCamlでも例外は依然軽量であることを示している。 後者は実行モデルの変更に大きく影響されている。
5-1-1. OTSSとreasonable red zone size
Red zoneを0 wordsにした場合、OCaml text section size(OTSS)6が0 wordsだと元のOCamlよりも30%大きくなる。 一方32 wordsと16 wordsでは同じ19%増加と変わりなく、実行時間もほとんど違いはない。 したがって、OTSSのサイズを縮小するためにもred zoneは16 wordsにするのが一番良い。
5-2. With effects
5-2-1. No perform
Effectを利用する場合のベンチマークを取るために、まずはeffectを発生させずにハンドラだけ導入するプログラムでベンチマークを取った。 比較のため、concurrency monadをCPSで実装したライブラリを利用している。 (おそらく末尾呼び出し最適化防止のため)末尾呼び出しになっていない関数呼び出しをハンドルするプログラムになっている。 ハンドラを使うと、使わない場合に対して10倍、concurrency monadの場合67倍実行時間が増加した。 Concurrency monadは継続にheap allocationが必要になる一方、effect handlersはstack allocationで済む。 このことはLwtやAsyncなどにも言えることで、continuation fiberがheap-allocatedだとbacktraceやDWARF unwindingなどが得られないなどのデメリットがある。
5-2-2. Concurrency benchmark
実際にWebサーバを実装するベンチマークでは、 Lwtライブラリをつかった実装、Goによる実装とスループット、tail latency7の比較をおこなった。
Effect handlersを利用した実装では、リクエストごとにスレッドがspawnする。
OCamlの両実装ではhttpafとlibevを使う。
Lwtは先述のとおりmonadicなAPIを提供している。
Go(1.13)はnet/httpを利用し、並列実行はしない(GOMAXPROCS=1)。
スループットは3つとも横並びだったが、tail latencyに関してはMulticore OCamlが最も良く(17ms/99.9985 percentile)、Lwtが最も悪かった(22.5ms/same)。 先述の通り、Lwtはbacktraceが取れない一方Multicore OCamlのeffect handlersはcontinuationのbacktraceが得られる点は考慮すべきで、リクエストごとに対してbacktraceが得られるのはデバッグに大いに役立つだろう。
6. おわりに
かなりつまみ食いしたので文脈に穴が空いている部分が多く(continuationみたいですね!)読みづらい感がなくもないが私は満足しました。 今回は触れなかったが、外部呼び出しに関するeffortとかOCamlとCのcall stackが単一になっている実行モデルをdynamic semanticsで示している4章も結構おもしろい。 また、OCaml 5.0のもう一つの目玉であるparallelismに関する論文もあるので8、ぜひ読んでみてください。
-
KC Sivaramakrishnan, Stephen Dolan, Leo White, Tom Kelly, Sadiq Jaffer, and Anil Madhavapeddy. 2021. Retrofitting effect handlers onto OCaml. In Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation (PLDI 2021). Association for Computing Machinery, New York, NY, USA, 206–221. https://dl.acm.org/doi/10.1145/3453483.3454039 ↩
-
例えばJavaやGoはエラーの詳細等のためにcallee-saved registersを利用するらしい(Wiki調べ) ↩
-
この辺を参照: https://rust-hosted-langs.github.io/book/chapter-simple-bump.html ↩
-
OCamlの例外は速いため、しばしばループや再帰などを抜けるためにも使われる。記事中にもあるとおり、backtraceを生成しない
raise_notraceという関数を使うと一層速い ↩ -
"We define OTSS as the sum of the size of all the OCaml text sections in the compiled binary file ignoring the data sections, the debug symbols, the text sections associated with OCaml runtime and other statically linked C libraries" ([1] より引用) ↩
-
KC Sivaramakrishnan, Stephen Dolan, Leo White, Sadiq Jaffer, Tom Kelly, Anmol Sahoo, Sudha Parimala, Atul Dhiman, and Anil Madhavapeddy. 2020. Retrofitting parallelism onto OCaml. Proc. ACM Program. Lang. 4, ICFP, Article 113 (August 2020), 30 pages. https://doi.org/10.1145/3408995 ↩
投稿されたコメントはCC BY 4.0ライセンスの下で公開されます。